Research Data Management
Research data management (RDM) can help you keep your data organized, well-documented, and secure so that you can easily find, understand, share, and reuse it at any time. This guide provides a brief introduction to research data, RDM practices (for efficient data organization, documentation, storing, sharing, and RDM planning), and commonly accepted FAIR Principles. It includes recommendations for creating a data management plan and sharing data using repositories. Links in this guide will navigate you to additional information, tools, support, and resources to maximize the efficiency and quality of your research process.
Research data is any information or material that has been collected, used, or generated during the research process. Research data is needed to produce, support, or validate research findings, and it provides the evidence for published results.
Research data can take many different forms (both digital and physical), including numerical data, images, text documents, software code, audio recordings, videos, surveys, protocols, samples, and many more. Forms and specifications for data can vary across fields and disciplines (e.g., natural sciences, life sciences, social sciences, arts and humanities).
Why Manage Research Data?
Research data is a valuable resource that typically requires a lot of work, time, money, and effort to produce. Therefore, it is important to manage your data properly to keep it secure and organized. Well-managed data is easy to find, access, understand, use, or reproduce, even over time and by others. Research data management (RDM) can make your research process more efficient and it is often required or recommended by institutions, publishers, or research funders.
Do you need assistance with RDM or have any other questions? Contact us for a free-of-charge individual consultation. We also regularly offer a webinar “Introduction to Research Data Management”. For more information about upcoming webinars, please see our webinar schedule.
Key benefits of good RDM practice include:
- Organized, secure, smooth, and efficient research process, including:
- Ability to locate, identify, and understand data quickly
- Efficient and secure sharing of data with colleagues and collaborators
- Improved data security (e.g., less risk of data loss, leaks, or unwanted disclosures)
- Saving time and resources (e.g., by eliminating inefficient file searching or recollecting lost data)
- Maintaining research integrity
- Continuity of research in the long run for cases where the transfer of data between researchers is expected
- Support of public data sharing (in accordance with Open Science and FAIR Principles) and related benefits:
- Potential new uses of data (e.g., for new analyses or as a resource for education)
- Improved replicability and reproducibility of research results
- New opportunities for collaboration
- Enhanced visibility and impact of research results
- Increased transparency that helps to build trust in research findings
- Improved validation of research results
- Compliance with data management requirements and policies developed by:
- Institutions (e.g., Charles University, J. Heyrovský Institute of Physical Chemistry)
- Journals and publishers (e.g., Springer Nature, Wiley, PLoS)
- Research funders and individual funding programs (e.g., European Union funding programs, the Czech Ministry of Education, Youth and Sports, the Czech Science Foundation, the Technology Agency of the Czech Republic)
Research Data Lifecycle
Research data passes through different stages during the research process. It can be described and visualized using a data lifecycle model (e.g., RDMkit, UK Data Service). This model is often used as a tool to help researchers map individual data stages, including data collection, processing, analysis, preservation, publishing, and reusing.
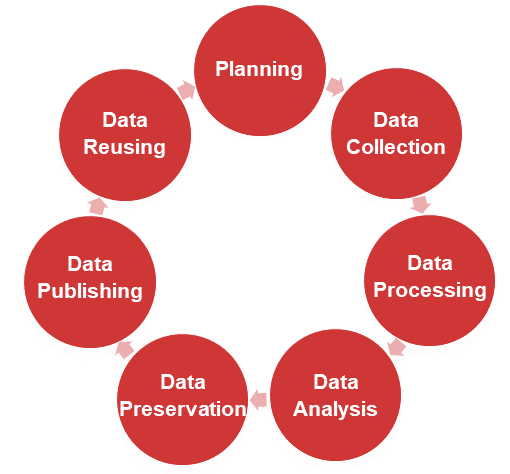
Deeper insight into each stage of the research process can reveal specific data-related requirements and identify appropriate data management practices to ensure efficient data organization, documentation, storage, and sharing. Deciding which practices and strategies to implement, when and how, should be done during the planning phase.
In reality, the research process is not necessarily so strictly ordered, and individual stages may occur simultaneously or some may be absent depending on nature of the data, project requirements, experiments performed, or standards in your discipline.
The FAIR Principles refer to a set of four fundamental guiding principles for research data (Findability, Accessibility, Interoperability, and Reusability) further described in fifteen detailed elements. The principles define what characteristics the data, metadata, tools, and infrastructures should have to improve data discovery and reuse. The principles are sufficiently general to be applied to a wide range of research outputs in all disciplines and do not prescribe any specific tools or technologies.

Adapted from Wilkinson, M.D. et al., 2016
Research funders increasingly require publicly funded data to be openly available (“as open as possible, as closed as necessary”) and in compliance with the FAIR Principles. Open data refers to data that is freely accessible and available for use for any purpose by anyone. There may be legitimate situations where data access needs to be restricted for legal, ethical, or security reasons (e.g., personal data protection, confidentiality, or intellectual property rights). The FAIR Principles do not require any data to be strictly open or fully available. However, when access needs to be restricted, this should be clearly specified.
There are several tools available online to help you make data “more FAIR” (e.g., FAIRification workflow, FAIRification framework, FAIRification process). You can also validate “how FAIR” your data is using various tools (e.g., F-UJI, FAIR DataSet Maturity assessment tool, FAIR data self-assessment tool, FAIR-Checker). The Data Stewardship Wizard tool shows FAIR metrics during the data management plan creation.
More information on the FAIR Principles can be found in, e.g., How to FAIR, GO FAIR, FAIRsFAIR, or FAIR Cookbook.
Research data management (RDM) is a set of practices, strategies, activities, tools, and techniques that ensure the proper organization, documentation, storage, and sharing of data during the research process. RDM helps keep your data secure and makes it easier for you and others to find, access, understand, use, or reproduce your data. RDM should cover the entire data lifecycle and is also associated with responsible data management planning.
Please note that RDM is an evolving field, and new recommendations and policies are emerging at the individual university, research institution, funder, and publisher levels. In addition, RDM is discipline-specific and there may be standards in your field that need to be followed (for more information see e.g., FAIRsharing).
If you need assistance with your RDM or have any other questions, please contact us for an individual consultation. We also regularly offer a webinar “Introduction to Research Data Management”. For more information about upcoming webinars, please see our webinar schedule.
At first, RDM may seem like a lot of extra work, however in the long run, it can save a lot of time and provide many benefits. There is no single right way to manage data; rather, you can incorporate a series of small routine practices specifically into your work to improve the efficiency and quality of your research process. Once you choose the right practice for you, it is essential to use it consistently.
Data management planning should start in the early stages of the research project as part of the project design. During planning, all data-related activities should be considered in detail, such as solutions for data storage and documentation, plans for data sharing, publication, and long-term preservation as well as potential legal and ethical issues. Creating a data management plan (DMP) can help address these aspects. Moreover, a DMP may be required by research funders when applying for funding.
Data organization includes using a logical folder structure and a consistent system for file naming and versioning to help locate and identify data easily.
For example, it is recommended that file names be short but meaningful, without spaces and special characters. Also, using version numbers or dates (always in the same format) in file names allows you to keep track of file modifications and to sort files accordingly (there are tools and software for automatic version control; e.g., Git).
More tips and suggestions about file naming, versioning, and data organization are provided by, e.g., the University of Ottawa, the University of Edinburgh, RDMkit, and Mendel University.
Data documentation should provide clear and complete information to ensure that the data can be understood, reused, reproduced, or replicated by you (or others, when sharing). A comprehensive guide on documentation from Helsinky University Library is a great place to start.
During a research project it is important to record all details about data collection, processing, and analysis (e.g., samples, materials, experimental methods and procedures, and instruments and software used), usually using reporting protocols and paper or electronic lab notebooks (ELNs). ELNs (e.g., Kadi4Mat, openBIS, Chemotion, eLabFTW, Jupyter Notebook, or NOMAD) are software tools that help to document, organize, store, and share the data, notes, and protocols more efficiently.
For each dataset it is a good practice to create a README file providing all relevant information about the dataset (e.g., list of files and description of their contents) and store it along with the dataset (for further details see, e.g., Cornell’s guide to writing README, Harvard Medical School’s guide, the MIT README sample and template, or the Great Learning Blog).
Explanations of abbreviations, codes, symbols, variable names, or units of measurement used during the project can be embedded directly within data files or kept separately in a codebook or data dictionary (for guides and examples see, e.g., McGill’s Codebook cookbook or OSF guide on How to make a data dictionary).
Metadata description provides information about data (including e.g., dataset title, creator, description, keywords), typically in a structured and defined format that enables findability of data when it is deposited in a public repository.
A reliable data storage and backup system as well as strategies should be in place to ensure data security and to protect data from potential loss, damage, unauthorized access, or unwanted disclosures.
It is important to distinguish between the storage of frequently accessed data that is in constant use during the active phases of a research project (data collection, processing, and analysis), and the long-term preservation of data, where further modifications are not expected (e.g., deposition in a data repository).
Regular data backups should be ensured (additional copies of data should be stored in various locations separated from your working files and accessed only to restore the original data in case of data loss or damage). One of the commonly used backup strategies is the 3-2-1 rule (i.e., keep 3 copies, on 2 different types of storage devices, with 1 copy off-site).
During the storage process, you can increase security of data by appropriate access controls or by data encryption.
There are several general guides that provide tips on data storage and security (e.g., ”Data storage and security” book chapter by C. Lewis) and on deciding what data to keep, for how long, and where (e.g., ”Five steps to decide what data to keep” section of DCC guide, “Preserving” section of RDMkit or Data Repositories tab).
Most universities and research institutions have own policies or methodological guidelines on how to store and secure data (e.g., the University of Chemistry and Technology Prague, Charles University, Mendel University, Masaryk University). These often include data categorization based on the level of sensitivity of the data, special regulation or protection requirements (e.g., legal or contractual), and the level of potential harm caused by data disclosure. These also provide an overview of data storage options and related recommendations for individual storage systems.
For academic researchers and students at research institutions in the Czech Republic, the CESNET Association offers data storage services for research purposes, provided that users comply with their Terms of Service. Services include storage environment for data backup, archiving, sharing, and other services such as Object storage, FileSender, or ownCloud.
A data management plan (DMP) is a document that summarizes all the details of research data management for an individual research project. Before starting a new project, it is important to consider all data-related aspects to ensure efficiency of the research process, avoid or minimize problems, and anticipate how potential problems might be addressed. Creation of a DMP can help ensure that data is managed properly during all stages of the project and in accordance with FAIR Principles. In addition, when applying for funding, a DMP is increasingly required as a formal part of a grant proposal or at later stages of the project.
DMP Tools and Templates
Specific DMP templates may be required or recommended by individual research funders and funding programs (e.g., Horizon Europe) or some research institutions (e.g., the J. Heyrovský Institute of Physical Chemistry).
There are several online tools (e.g., DMPonline, Argos, or Data Stewardship Wizard) that can help you prepare a DMP for any project. In addition, these tools allow you to save and edit a DMP, share it with collaborators and export a final version into a required template. For instructions on how to use these tools, you can view one of the online tutorials (e.g., EOSC CZ webinar or DSW tutorials).
RDM planning is an active process that evolves over time and can change with new research findings; accordingly, a DMP should be updated regularly.
Topics often Included in a DMP
The structure and content of a DMP may vary according to the requirements of individual research funders or institutions. In general, a DMP should include details covering (but not limited to) the following:
- General information
- Project title
- Funding information
- Short project description (abstract)
- Description of the research team (names, affiliations)
- Data description
- Origin of data (collection of new data or reuse of existing data)
- Expected data types, file formats, and sizes
- Purpose of new data generated and its intended use
- Data documentation
- File naming and versioning conventions
- Methods, instruments, and software used to collect, process, and/or analyze data
- Type of documentation used (e.g., README files, protocols, codebooks, lab notebooks)
- Data quality control procedures (e.g., calibrations, repeated measurements)
- Data storing and archiving
- Plans for data storage and backup (including storage procedures and facilities)
- Expected storage capacity requirements and related expenses
- Data security and protection plan (e.g., off-site backup, recovery in case of accidents)
- Data sharing and publication
- Access rights (e.g., open access, restricted access, time embargo)
- Data deposition in a repository, metadata descriptions
- Use of persistent identifiers
- Data licensing
- Legal and ethical aspects of RDM
- Potential legal and ethical issues (e.g., research involving personal, confidential, sensitive, or third-party data)
- Relevant legal and ethical requirements (e.g., data anonymization, pseudonymization, encryption, restricted or controlled access, time embargos, collaboration agreements, ethical approval, consent of participants)
- Compliance with laws, regulations, policies, and ethical guidelines
- RDM roles, responsibilities, and resources
- Expenses dedicated to RDM (e.g., costs related to storage, archiving, security, staff time and salary)
- Roles and responsibilities assigned for RDM/data stewardship activities
- Adherence to FAIR Principles
- Regular DMP updates
For more details, see, e.g., the Science Europe Practical guide or the Horizon Europe DMP template.
Data repositories are storage locations for long-term preservation of research data (and publications). Repositories can also facilitate data sharing and publishing by providing access to data, if applicable. Data repositories often have a predefined structure and their own rules and standards for deposition, storing, and sharing data (see also the Data Sharing section).
Data Repository Selection
Most research funders and publishers have data sharing policies. These often require the deposition of research data in an appropriate data repository to make it publicly available. Sometimes a list of recommended repositories is provided (e.g., by Springer Nature, F1000Research, PLoS). Depending on the data type and disciplinary specifications, a suitable repository can be selected by searching one of the available registries or directories (e.g., re3data or FAIRsharing).
General recommendations for choosing a suitable repository are:
- A discipline-specific and community-recognized repository is recommended, if available (e.g., PANGAEA for earth and environmental sciences, the NOMAD Repository for materials science, HEPData for physics, SEANOE for ocean sciences). In addition, for certain data types deposition into a specific repository is mandatory (e.g., the Protein Data Bank for macromolecular structure data or UniProt for protein sequence data) as specified in individual journal guidelines (e.g., Springer Nature’s mandated data types).
- Alternatively, an institutional repository may be used if provided by one’s home university or research institution (e.g., the ASEP Repository).
- In other cases, a cross-disciplinary generalist repository can be used (e.g., Zenodo, Figshare, Dryad).
Data Deposition
Before data deposition, it is important to consider several things to make the process easier. Requirements for data deposition vary across repositories, so it is advisable to get familiar with the standards and deposition process used by your chosen repository. Follow the instructions and guides and prepare all files, information about your dataset, and any related documentation required for submission to the repository.
Some considerations and common recommendations for data deposition (to enhance compliance with the FAIR Principles):
- Data should be deposited in an appropriate format, preferably in a non-proprietary open format commonly used in the field and interoperable among various applications (for recommendations, see, e.g., the UK Data Service, How to FAIR, DANS, or RDMkit).
- Data should be supplied with all relevant documentation (such as a README file; see Data Documentation section) to ensure it can be understood and reused.
- An appropriate license should be applied to the data (see Data Sharing section).
- There may be reasons why some data cannot be shared publicly (e.g., sensitive data). If this is the case, appropriate solutions are needed. Some repositories offer controlled access to data.
- Typically, data is assigned a persistent identifier (PID, most commonly DOI) by a repository upon deposition. This PID should be included in the associated publication (as a part of a data availability statement) to link both items together. In addition, associating more PIDs with your data (e.g., ORCID iD or Research Resource Identifiers) connects all related resources. This makes them easier to identify, enables citation of research outputs and provides publication records for data creators.
Please note that for some repositories, there may be size limits for file uploads or fees for storing a large volume of data (or other services).
If you need help with RDM, there are a number of ways to get support. Some suggestions are provided below.
Home Institution Support
Most universities and research institutes provide RDM support through their own Open Science center or portal (e.g., the Czech Technical University in Prague, the University of Chemistry and Technology Prague, Charles University, Mendel University).
There may be a data steward, responsible for RDM support at the institutional or research team level. Some form of advice may be available from librarians, lawyers, or members of the Technology Transfer Department, the Project Office/Grant Office/Project Center, or the IT Department.
NTK Support
NTK offers following RDM support and services:
- The Education and Research Support team offers support for undergraduate and graduate students as well as for early career researchers for the development of academic skills needed during the research process and in their future careers. Recently we have implemented RDM into our portfolio of webinars and consultations.
- The Center for Repositories and Metadata Management provides support with metadata management. A full list of services is available here (in Czech only).
- The National Center for Persistent Identifiers provides administrative, coordination, methodological, and financial support for the introduction and use of persistent identifiers compatible with European and international standards (ISSN for periodicals, ORCID iD for researchers, DOI for objects, ROR for institutions, and IGSN ID for samples).
If you have any questions about RDM or related issues, please contact us for an individual consultation.
Books in the NTK Collection
NTK Material
- Introduction to Research Data Management: 2 hr recording of the NTK webinar & slides focused on basic RDM overview (e.g., research data lifecycle, FAIR Principles, RDM practices for data organization, documentation, storing, and sharing).
- identifikatory.cz: Web maintained by the National Centre for Persistent Identifiers in cooperation with the National Library of the Czech Republic that provides information about persistent identifiers (ISSN for periodicals, ORCID iD for researchers, DOI for objects, ROR for institutions, IGSN ID for samples, ISBN for books, RAiD for research activities or projects, and others).
- STEMskiller: A structured, comprehensive, annotated, hyperlinked map to high-quality, openly accessible sources of information for (early career) researchers. The Research Data section covers topics such as data management and sensitive data.
- Obecné doporučení pro metadatový popis výsledků výzkumu (zejména publikací a dat): General recommendations for metadata description of research results when deposition in a repository (in Czech only).
Online Courses
- Data Steward Training (EOSC-Synergy). This online course aims to support the development of data stewardship skills among staff in Higher Education Institutions and other research performing organizations.
- Data Stewardship – Module 1: MOOC (DocEnhance). This theoretical part of the Data Stewardship course for PhD candidates provides an introduction to RDM.
- EOSC CZ Training Centre organizes training courses in the Czech Republic and offers an archive of past events and materials (focused on FAIR data, Open Science, legal aspects of RDM, licensing, metadata, etc.).
- Elixir CZ. Short (2–5 min) videos on different basic topics in RDM.
Guides
- FAIR Handbook for the Data Steward Community in the Czech Republic (EOSC).
A guide intended mainly for beginning data stewards. Not only does it explain the FAIR principles, but it also demonstrates how to fulfill them in practice. In addition, the handbook provides information on selected technical aspects of research data management (RDM). - Beginner’s Guide for Data Stewards (EOSC). Short manual primaraly for institutional/project data stewards who are new to their role.
- RDMkit (ELIXIR). An online guide for life scientists based on the data lifecycle model that provides RDM guidelines, best practices, and examples, as well as resources for various RDM tools.
- Data Management Expert Guide (Consortium of European Social Science Data Archives, CESSDA). An online RDM guide for social science researchers. An offline version can be also downloaded as a pdf document (CESSDA Data Management Expert Guide, CESSDA, 2020).
- Managing and Sharing Data: Best Practice for Researchers (UK Data Archive, University of Essex, 2011). A guide covering major aspects of RDM, such as data sharing, planning, documenting, formatting, storing, and ethical and copyright issues. Data management checklist is also included.
- Making a Research Project Understandable – Guide for Data Documentation (Fuchs, S.; Kuusniemi, M. E., 2018). A compact guide for researchers on how to document research data.
- Data Management in Large-Scale Education Research (Lewis, C., 2024). A free online version of the eponymous book serving as a practical guide to data management, including real-world examples, templates, and checklists.
- The Research Data Management Workbook (Briney, K., 2023). A collection of exercises covering the entire data lifecycle designed to improve research data management.
Articles
- Kanza, S.; Knight, N. J. Behind Every Great Research Project Is Great Data Management. BMC Research Notes 2022, 15 (1), 20. https://doi.org/10.1186/s13104-022-05908-5.
- Briney, K.; Coates, H.; Goben, A. Foundational Practices of Research Data Management. Research Ideas and Outcomes 2020, 6, e56508. https://doi.org/10.3897/rio.6.e56508.
- Wilkinson, M. D. et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Scientific Data 2016, 3 (1), 160018. https://doi.org/10.1038/sdata.2016.18.
Your contact

